Download Stock Data from LSEG Workspace in Python
There is LSEG documentation, but not a simple end-to-end script you can copy, paste, and run. So I put one together.
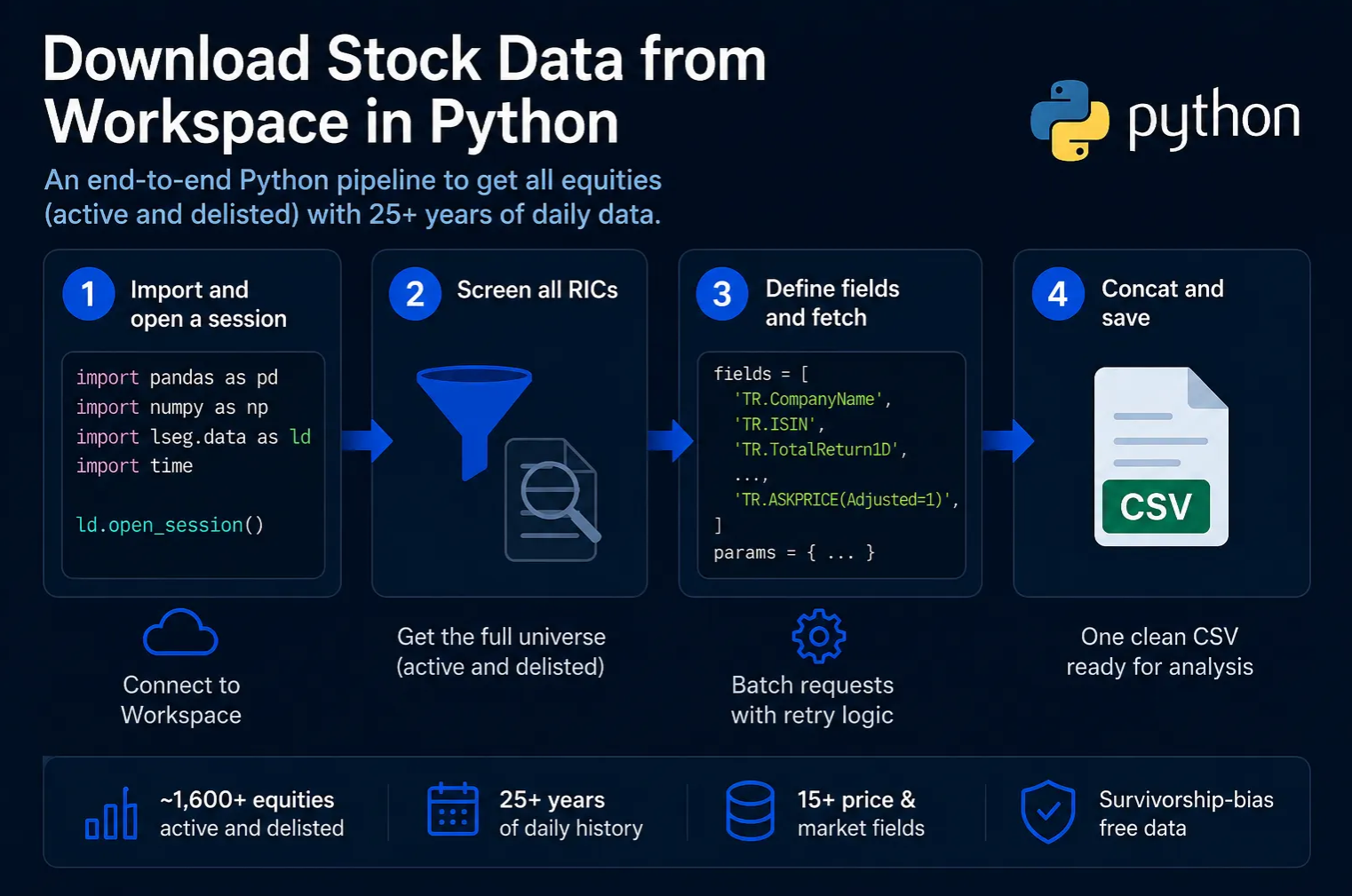
It walks through four steps, from starting a session to saving everything in one CSV. I use Sweden as the example. Swap the country code and it works anywhere LSEG has coverage.
Each block is ready to run as written. If you have access to LSEG Workspace, the pipeline works as is.
What you end up with
- ~1,655 Swedish equities, active and delisted
- 16 price and market fields, daily frequency
- 25+ years of history in SEK
- One clean CSV, survivorship-bias free
Step 1. Import and open a session
Four imports. One session. Done.
import pandas as pd
import numpy as np
import lseg.data as ld
import time
# Open connection to LSEG Workspace
ld.open_session()You need an LSEG Workspace license. The lseg.data Python API comes bundled with it.
Step 2. Screen all RICs
RIC is LSEG’s instrument code. Think ticker, but globally unique.
One API call returns the full Swedish universe, active and delisted. That is the key piece. Without the delisted names you have a survivorship-biased sample.
screener = ld.get_data(
universe=(
'SCREEN('
'U(IN(Equity(active or inactive,public,private,primary))), '
'IN(TR.RegCountryCode,"SE"), '
'(Contains(TR.InstrumentListingStatusCode,"DEL") '
'OR Contains(TR.InstrumentListingStatusCode,"LIS"))'
')'
),
fields=["TR.RIC", "TR.ISIN"]
)
screener.columns = ['Instrument', 'RIC', 'ISIN']
rics = screener['RIC'].dropna().unique().tolist()
rics = [r for r in rics if r and str(r).strip()]Swap "SE" for any country code. "US", "GB", "DE", and so on.
Step 3. Define fields and fetch
I pull 15 price and liquidity fields per stock. Add or remove to taste.
fields = [
# Identifiers
'TR.CompanyName',
'TR.ISIN',
# Returns and date
'TR.TotalReturn1D',
'TR.TotalReturn1D.Date',
# Size and liquidity
'TR.CompanyMarketCap',
'TR.DailyValueTraded',
'TR.EV',
# VWAP (raw and split-adjusted)
'TR.TSVWAP',
'TR.TSVWAP(Adjusted=1)',
# Price range
'TR.LOWPRICE(Adjusted=1)',
'TR.HIGHPRICE(Adjusted=1)',
'TR.LOWPRICE(Adjusted=0)',
'TR.HIGHPRICE(Adjusted=0)',
# Bid and ask
'TR.BIDPRICE(Adjusted=1)',
'TR.ASKPRICE(Adjusted=1)',
]
params = {
'scale': 6, # millions
'SDate': '2000-01-01',
'EDate': '2025-05-31',
'Frq': 'D', # daily
'Curn': 'SEK',
}Tip: search SCREENER inside LSEG Workspace to look up field names, country codes, and currency codes.
Now fetch. LSEG throttles large requests, so you have to batch and retry.
BATCH_SIZE = 5
BATCH_DELAY = 1.0
results = []
errors = []
for i in range(0, len(rics), BATCH_SIZE):
batch = rics[i : i + BATCH_SIZE]
for attempt in range(3):
try:
df = ld.get_data(batch, fields, params)
if df is not None and not df.empty:
results.append(df)
break
except Exception as e:
if attempt < 2:
wait = 2 * (2 ** attempt) # exponential backoff
time.sleep(wait)
else:
errors.append({'batch': batch, 'error': str(e)[:200]})
time.sleep(BATCH_DELAY)For ~1,655 RICs at 5 per batch, that is 331 API calls. Plan for roughly an hour end to end.
Step 4. Concat and save
df = pd.concat(results, ignore_index=True)
df.to_csv('swedish_stocks.csv', index=False)That is it. Every Swedish equity since 2000, in one CSV, ready for backtesting.